




Data Science | Machinelearning [ru]
Статьи на тему data science, machine learning, big data, python, математика, нейронные сети, искусственный интеллект (artificial intelligence)
По сотрудничеству - @g_abashkin Related channels | Similar channels
16 576
subscribers
Popular in the channel
☕️ Latte: Latent Diffusion Transformer for Video Generation Новый трансформер скрытой диффузии...
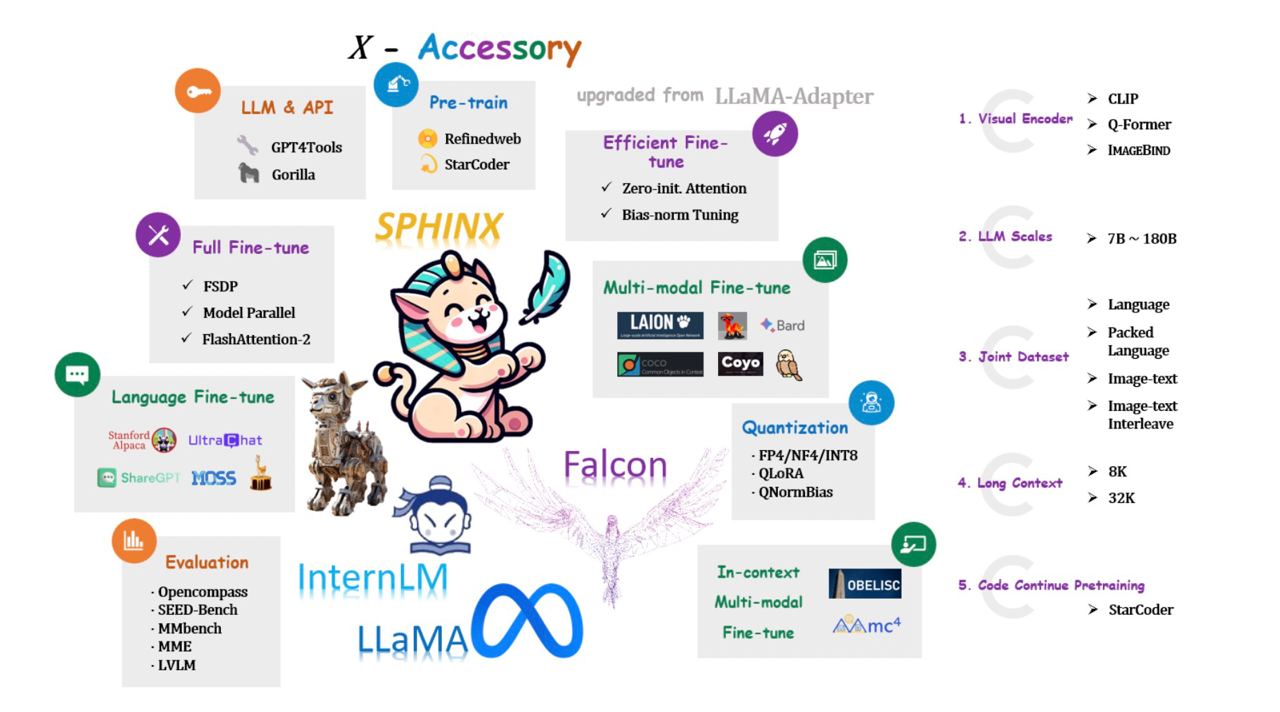
🏆 LLaMA2-Accessory: An Open-source Toolkit for LLM Development LLaMA2-Accessory — это набор ин...
ИЩЕМ Data Scientist/ ML Engineer в стартап из Кремниевой Долины. https://www.gotit.life/ Занято...

😁Когда тебя завлекают на роботу программистом) @Devsp — Подписаться
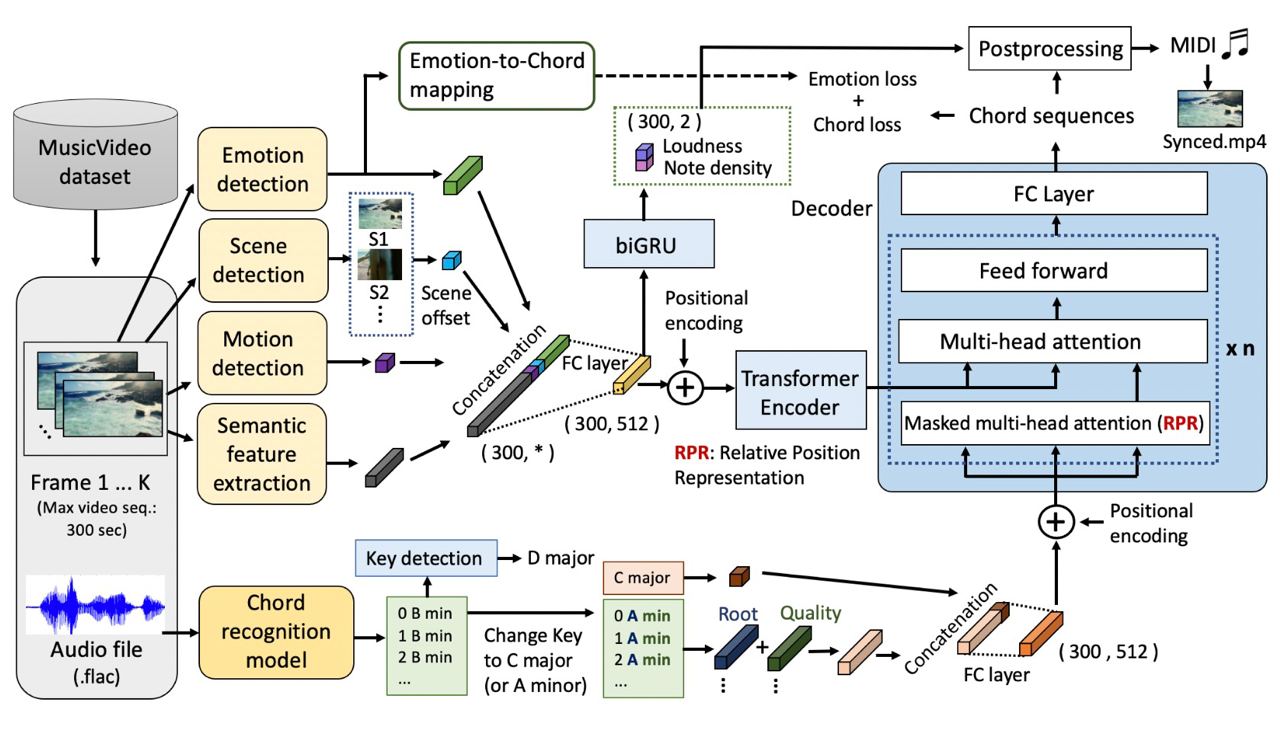
🎧Video2Music: Suitable Music Generation from Videos using an Affective Multimodal Transformer m...