
Как спарсить любой контент сайта с помощью Google Таблиц
Сегодня расскажу о полезных функциях, которые сильно упрощают работу с сайтами и информацией.
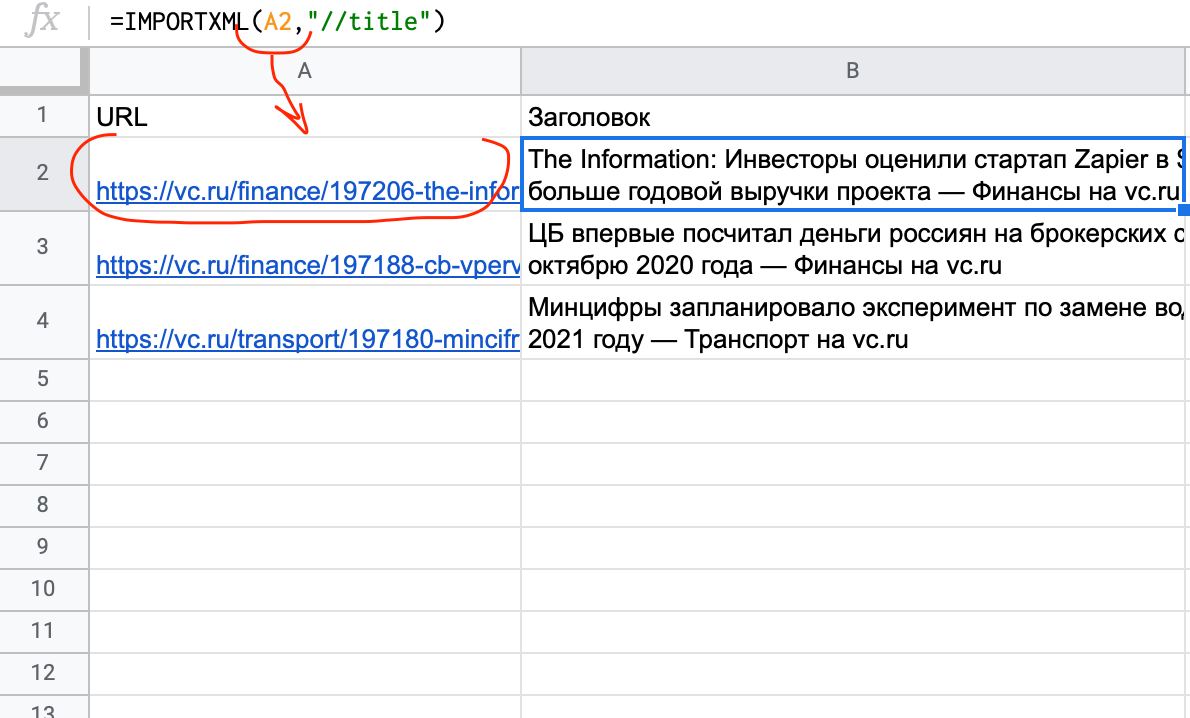
Например, у нас есть список урл и нужно по каждому вытянуть тайтл или описание. Открываем гугл таблицы, и в ячейке пишем следующую формулу
=IMPORTXML(url, "//title")
Вместо url подставляем адрес страницы. Если у вас вся колонка в адресах, то в формуле прописываем вместо url адрес каждой ячейки. (смотри скриншот)
Вместо //title можно ставить //h1, //h2, //description Тогда будет подтягиваться соотвествующая инфа.
Если нужно сделать что-то более сложное, то тут нужно уже смотреть стили сайта и прописать в формуле путь или атрибуты стиля. Для примера, мне нужно вытянуть со статей на VCru число прочтений каждой из статьи. Открываем код и видим, что эта информация выводится в теге view__value. Вот конкретный кусок кода статьи, у которой 3916 просмотров
...span class="views__value">3916...
И теперь мы в гугл таблицах пишем
=IMPORTXML(url,"//*[@class='views__value']")
То есть идет url (вместо которого ставим адрес своего сайта), а затем команда искать класс "views__value" и вывести в ячейке его содержимое. Для более сложных вариантов используется XPath
На самом деле формул очень много, но если разобраться с функцией IMPORTXML, то можно избавиться от кучи рутины. Вот простой рабочий пример
{kind=link}
Сегодня расскажу о полезных функциях, которые сильно упрощают работу с сайтами и информацией.
Например, у нас есть список урл и нужно по каждому вытянуть тайтл или описание. Открываем гугл таблицы, и в ячейке пишем следующую формулу
=IMPORTXML(url, "//title")
Вместо url подставляем адрес страницы. Если у вас вся колонка в адресах, то в формуле прописываем вместо url адрес каждой ячейки. (смотри скриншот)
Вместо //title можно ставить //h1, //h2, //description Тогда будет подтягиваться соотвествующая инфа.
Если нужно сделать что-то более сложное, то тут нужно уже смотреть стили сайта и прописать в формуле путь или атрибуты стиля. Для примера, мне нужно вытянуть со статей на VCru число прочтений каждой из статьи. Открываем код и видим, что эта информация выводится в теге view__value. Вот конкретный кусок кода статьи, у которой 3916 просмотров
...span class="views__value">3916...
И теперь мы в гугл таблицах пишем
=IMPORTXML(url,"//*[@class='views__value']")
То есть идет url (вместо которого ставим адрес своего сайта), а затем команда искать класс "views__value" и вывести в ячейке его содержимое. Для более сложных вариантов используется XPath
На самом деле формул очень много, но если разобраться с функцией IMPORTXML, то можно избавиться от кучи рутины. Вот простой рабочий пример