




Клуб CDO
Сообщество профессионалов в области работы с данными и искуственным интеллектом Связанные каналы | Похожие каналы
2 767
подписчиков
Популярное в канале
Довольно неплохой доклад про платформу управления данными. https://youtu.be/jYOWpcwfyTI?si=PsZW...
Опыт команды LinkedIn по внедрению GenAI в свой продукт: - "главное выбрать правильного агента" ...
Друзья! У нас есть неожиданное и очень приятное предложение от редакции канала CDO Club и команд...

https://www.nict.go.jp/en/press/2024/06/26-1.html
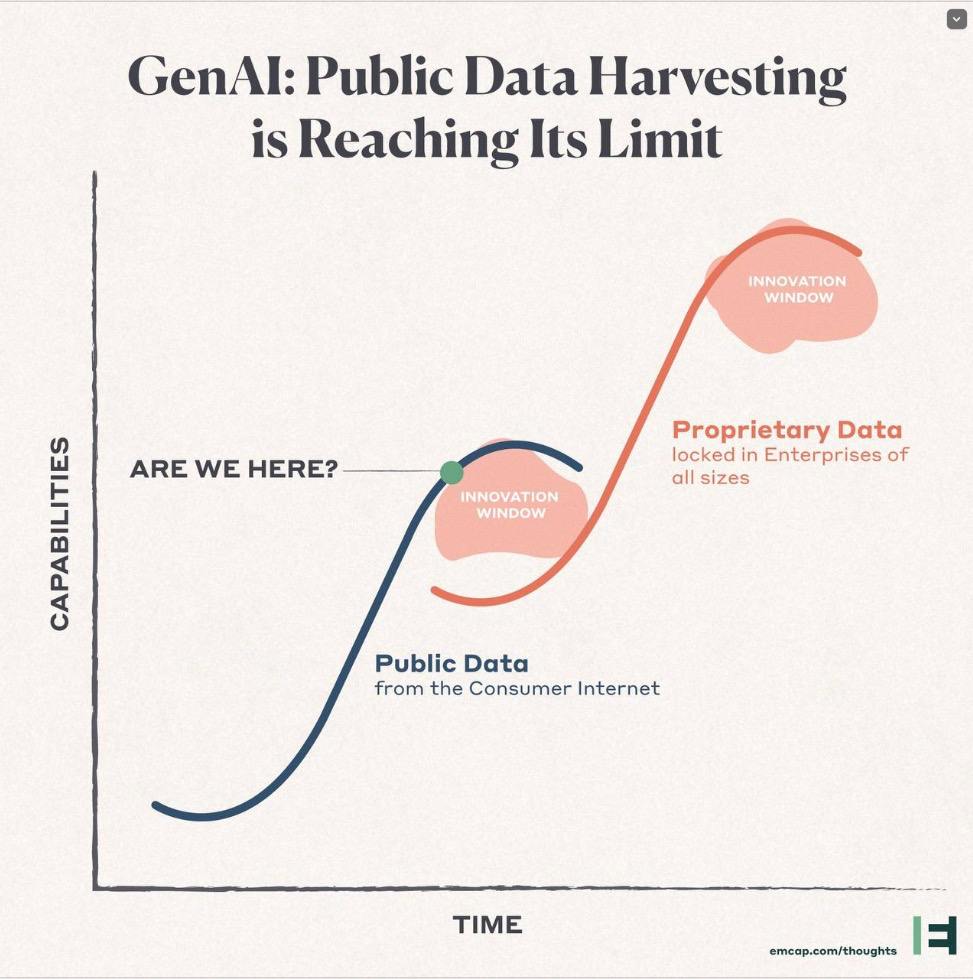
Пост #1982:
Фото