



Библиотека data scientist’а | Data Science, Machine learning, анализ данных, машинное обучение
Все самое полезное для дата сайентиста в одном канале.
Список наших каналов: https://t.me/proglibrary/9197
Учиться у нас: https://proglib.io/w/f83f07f1
Обратная связь: @proglibrary_feedback_bot
По рекламе: @proglib_adv
Прайс: @proglib_advertising Связанные каналы | Похожие каналы
18 669
подписчиков
Популярное в канале

🏝️ Решаем очень сложную SQL-задачу об островах и проливах Задача об островах и проливах — это кл...

⚕️ Какие специалисты по Data Science требуются в медицинских проектах и что им нужно знать? Что ...

👨🏫 Мишель Талагран: 5 советов молодым математикам Французский математик Мишель Талагран делится...
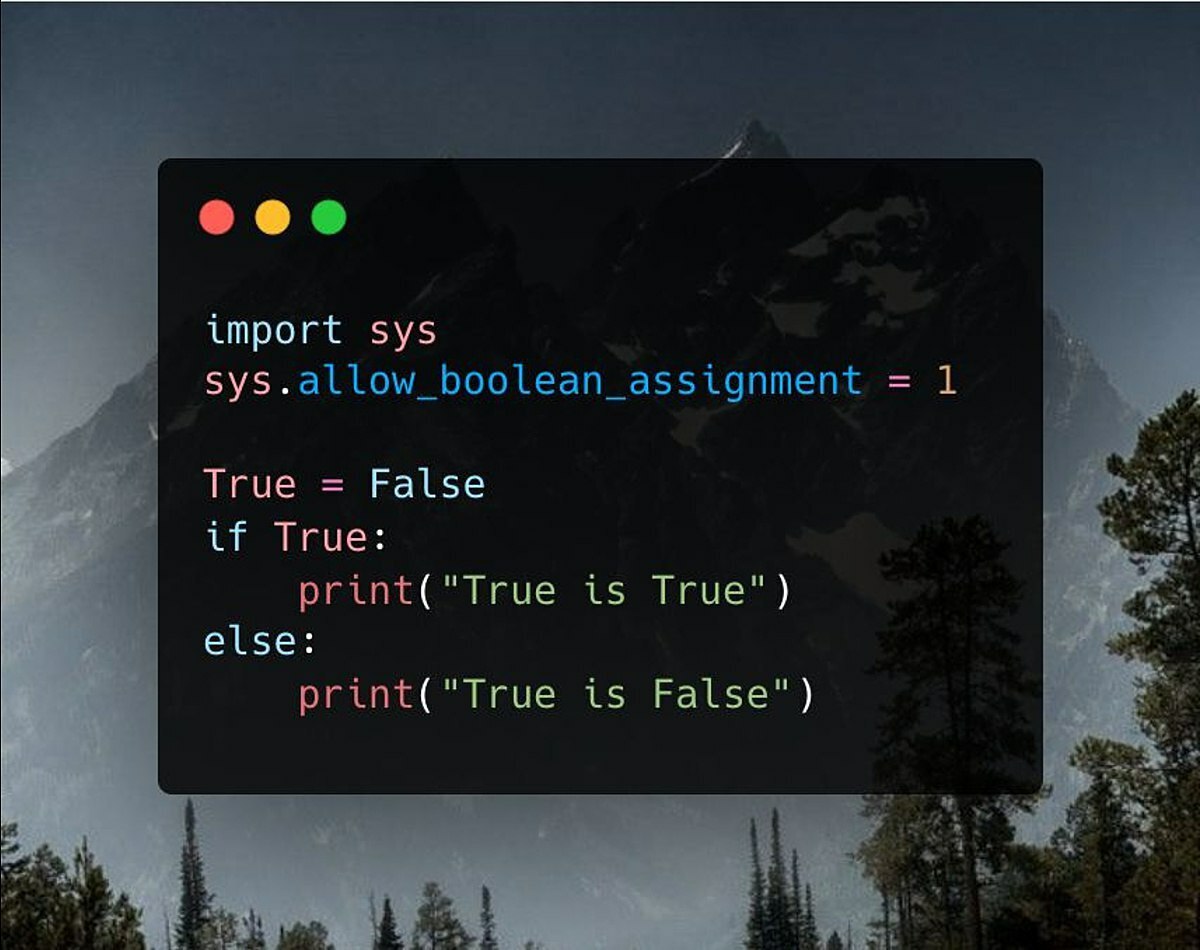
Запустится ли этот код на Python 3? Если да, то что он выведет? sys.allow_boolean_assignment раз...

🤖 Напоминаем, что у нас есть еженедельная email-рассылка, посвященная последним новостям и тенден...