



Love. Death. Transformers.
❤️☠️🤗
Указанные действия не являются ресерчем, поскольку:
а) Мы не ученые;
б) Оно работает.
@transformerslovedeatch по всем вопросам
Реклама от 1000usd, в противном случае прошу не беспокоить.
[18+] ответственность за прочитанное лежит на читателе Связанные каналы | Похожие каналы





14 835
подписчиков
Популярное в канале

Привет! Мы в лабараторию ебаного ресерча Vikhr models открываем летние стажировки Что по задачам...

Новый робот от китайцев из unitree теперь и с колесами!!
⚡️⚡️ Arxiv заблокируют в сентябре — об этом сообщает «Вестник науки.ру», ссылаясь на источник, бл...
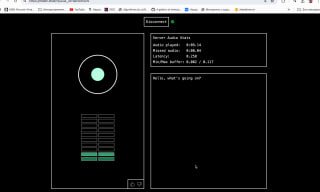
Вышла 4o у нас дома, стриминг аудио в обе стороны, перебивает и только английский. Играться ту...

И на последок минутка world modelling_а