
Кроме модели на 7 миллиардов параметров для соревнования, победители обучили ещё и модель на 72B (инициализированную из Qwen 2 от Alibaba) и выложили её (как и все даннные).
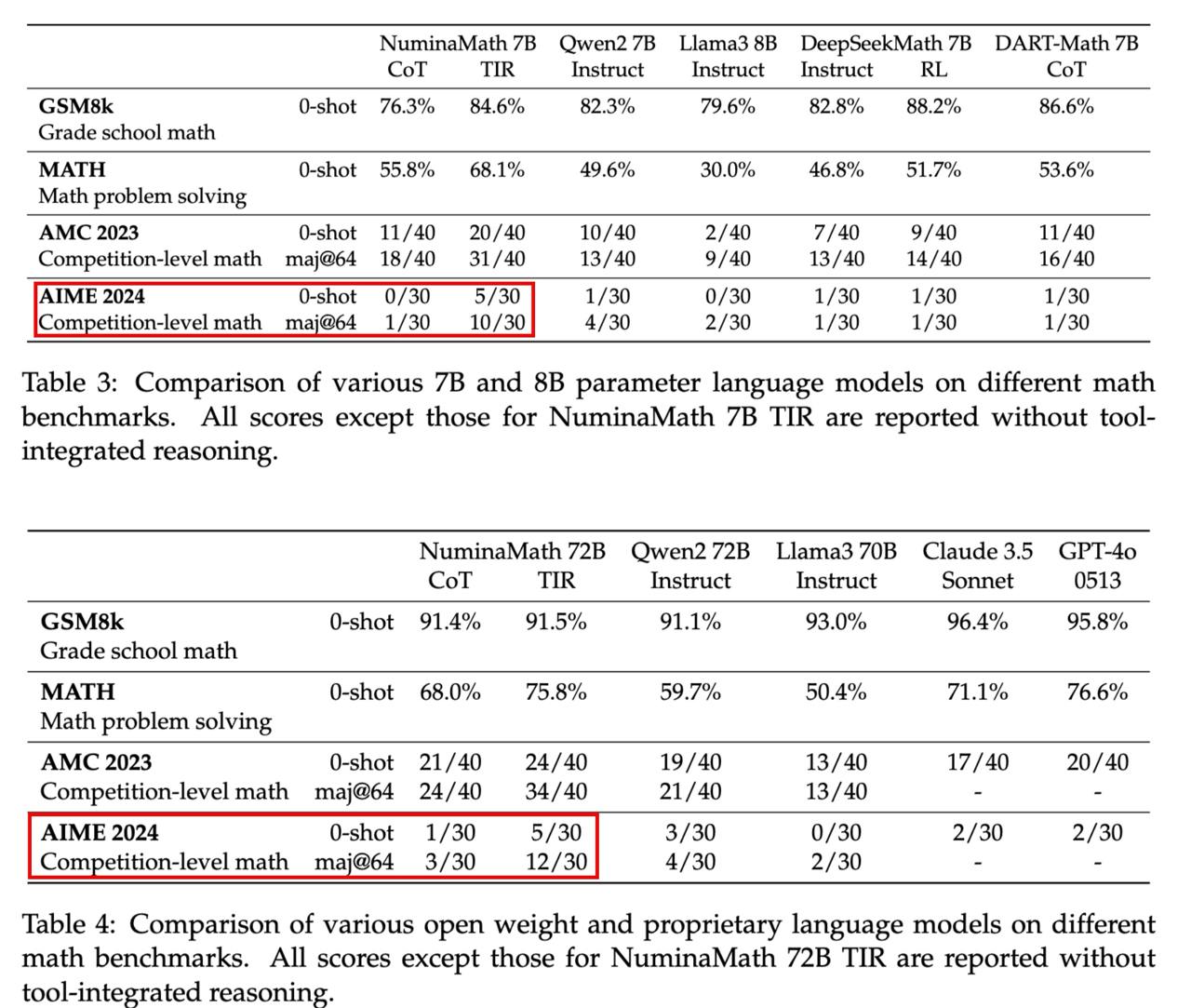
Результаты замеров и сравнений на картинке, сверху табличка для крохи 7B, снизу тяжеловесы.
0-shot — это когда модель сходу выдаёт первое попавшееся решение; maj@64 означает, что модель генерирует 64 решения (каждое решение = одна или больше Python-программа. Их получается несколько в том случае, если вылазит баг - тогда LLM пытается их исправить по тексту ошибки), а затем между всеми полученными ответами выбирается тот, который встречается чаще. Понятно, что во втором случае качество должно расти, что и наблюдается.
CoT = модель, обученная только на первом шаге, без написания кода программ (то есть и считает она сама, и может ошибиться даже в 2+2), TIR = с Python.
Самое интересное, пожалуй, смотреть на AIME 2024 как на самое свежее соревнование, где почти наверняка были новые задачки. А ещё на MATH — так как авторы очень старались отфильтровать похожие задачи и не тренироваться на них. 72B модель без кода показывает результат 68% при генерации ответа с первого раза. Это совсем чуть меньше 70.2%, которые были у свежей GPT-4o mini. По графику можно было подумать, что OpenAI переобучились, но видимо это достижимая планка через качественные данные и синтетику.
Результаты замеров и сравнений на картинке, сверху табличка для крохи 7B, снизу тяжеловесы.
0-shot — это когда модель сходу выдаёт первое попавшееся решение; maj@64 означает, что модель генерирует 64 решения (каждое решение = одна или больше Python-программа. Их получается несколько в том случае, если вылазит баг - тогда LLM пытается их исправить по тексту ошибки), а затем между всеми полученными ответами выбирается тот, который встречается чаще. Понятно, что во втором случае качество должно расти, что и наблюдается.
CoT = модель, обученная только на первом шаге, без написания кода программ (то есть и считает она сама, и может ошибиться даже в 2+2), TIR = с Python.
Самое интересное, пожалуй, смотреть на AIME 2024 как на самое свежее соревнование, где почти наверняка были новые задачки. А ещё на MATH — так как авторы очень старались отфильтровать похожие задачи и не тренироваться на них. 72B модель без кода показывает результат 68% при генерации ответа с первого раза. Это совсем чуть меньше 70.2%, которые были у свежей GPT-4o mini. По графику можно было подумать, что OpenAI переобучились, но видимо это достижимая планка через качественные данные и синтетику.